
- home
首页
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
RSS订阅
请注意,本文编写于 909 天前,最后修改于 907 天前,其中某些信息可能已经过时。
之前说的给这个系统套个前端放上来不太现实了,因为要检索的文档数据量有近3个G七十多万文档,我租的阿里小破服务器放不下所以对不起了又说了不切实际的话QAQ
MapRuduce过程:看这里或者这里
文档数据用的是这里
停用词用的这里和自己根据分词结果补充了一些,用的jieba分词包进行的分词
设计的是一个字典嵌套的结构
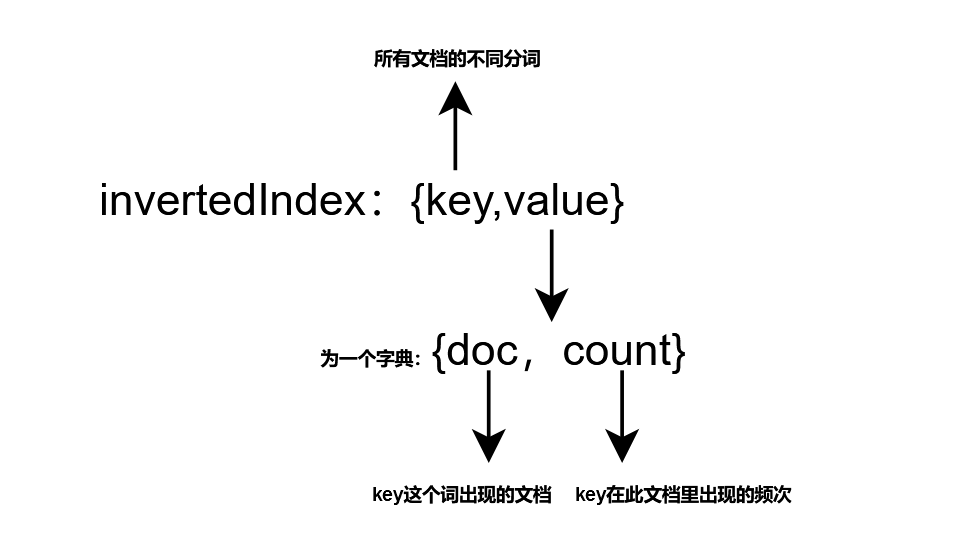
class docAndCount:
def __init__(self):
self.value={}构建索引的过程是
def addToDir(word,filename,currentDir):
global invertedIndex
if (invertedIndex.get(word))==None: #如果不存在这个词则添加新词进字典
temp=docAndCount()
temp.value[filename+' '+currentDir]=1#{‘文档名 文件夹’:频次=1}
invertedIndex[word]=temp
else: #存在这个词则频数加一,补充存在文件、目录
temp=invertedIndex[word]
doc=filename+' '+currentDir
if (temp.value.get(doc))==None:#如果这个词在这个文件中还没出现过
temp.value[doc]=1
else: #如果这个文件已经存在,则增加这个文件里此word的频数
temp.value[doc]+=1因为想把频次作为文档的相关性从大到小返回所以按照频次给索引的文档排了序
def wordSorting():
global invertedIndex
for word,value in invertedIndex.items():
after_order=sorted((value.value).items(),key=lambda x:x[1],reverse=True) #按照word的value的频次从大到小排序
invertedIndex[word]=dict(after_order)对用户实现了八种布尔查询,参考了这里(具体实现没有参考),返回的所有检索结果以及前三篇最相关文档的详细内容。
and_or和or_and的实现稍微有一点点点意思:
def merge3_and_or(key1, key2, key3):
global invertedIndex
answer = {}
if (invertedIndex.get(key1) == None) or (invertedIndex.get(key2) == None):
return answer
else:
for k, v in invertedIndex[key1].items():
if(invertedIndex[key2].get(k)!=None):
answer[k]=v+invertedIndex[key2][k]
if (invertedIndex.get(key3) == None):
return answer
for k,v in invertedIndex[key3].items():
if (answer.get(k) != None):
answer[k] += v # 定义相关性为三者频数之和
else:
answer[k] = v # 如果没有则加入
return answer
def merge3_or_and(key1, key2, key3):
global invertedIndex
answer = {}
if (invertedIndex.get(key1) == None):
return answer
for k, v in invertedIndex[key1].items():
answer[k] = v
if (invertedIndex.get(key2) == None) or (invertedIndex.get(key3) == None): #没有key2或者key3,返回key1的结果即可
return answer
else:
for k, v in invertedIndex[key2].items():
if (invertedIndex[key3].get(k) != None): #说明可以满足key2和key3
if(answer.get(k)!=None) :#这个文档同时满足key1
answer[k] += v+invertedIndex[key3][k] # 定义相关性为三者频数之和
else: #只满足key2和key3
answer[k]=v+invertedIndex[key3][k] #定义相关性为两者频数之和
return answer效果就是预期的那样吧
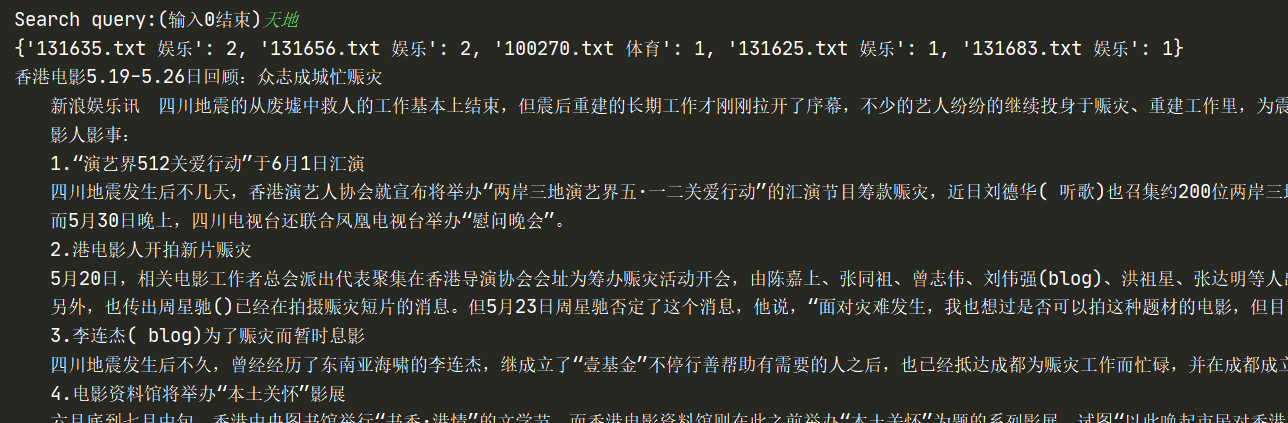
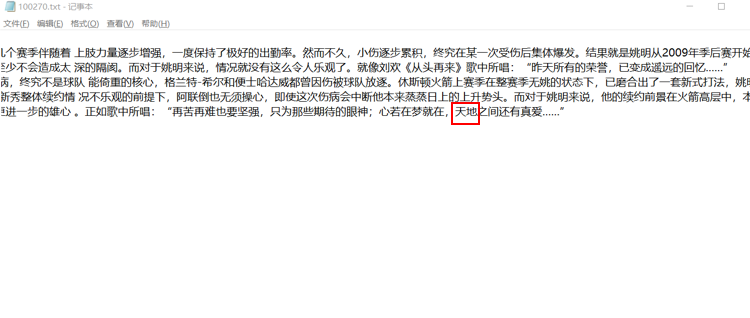

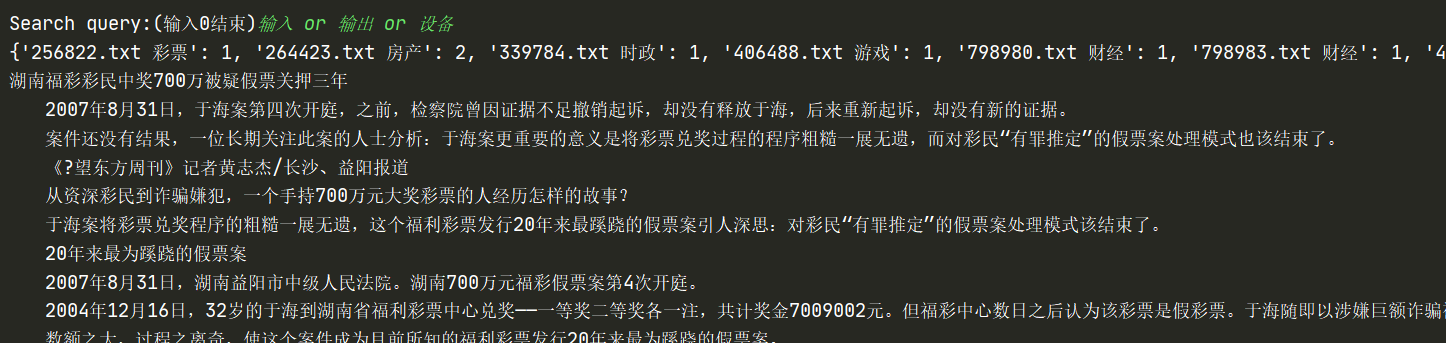
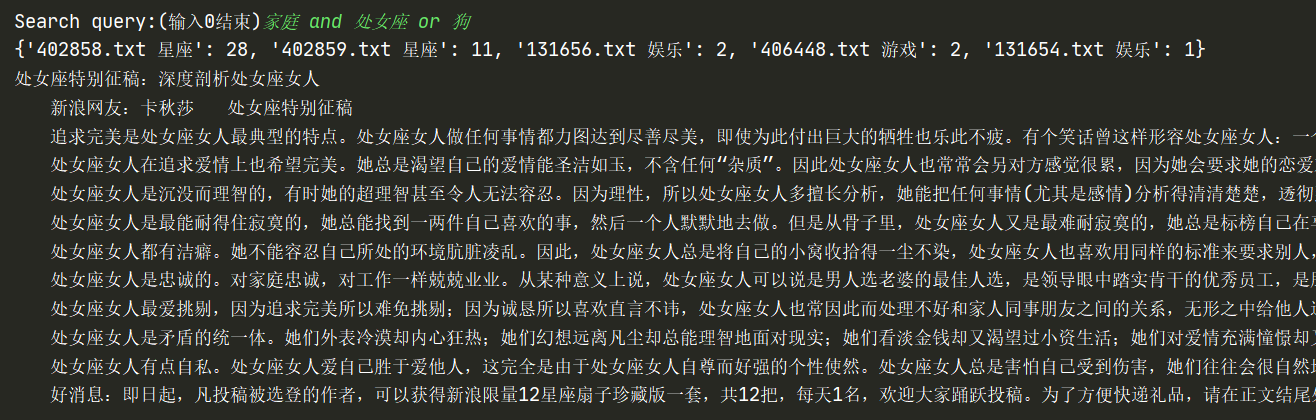
jieba分词效果也挺好的

没用到什么复杂的东西,不管什么语言面向对象还是过程对我来说永远只会从上往下写。。。也许我该去看看设计模式,但实现的时候还是很激动,不到三百行的代码就可以实现对七十多万文档的简单检索,信息时代的我好幸福(好吊丝啊。。。









































































































全部评论 (暂无评论)
info 还没有任何评论,你来说两句呐!