
- home
首页
-
view_list分类keyboard_arrow_down
-
access_time归档keyboard_arrow_down
-
view_carousel页面keyboard_arrow_down
rss_feed
RSS订阅
请注意,本文编写于 1313 天前,最后修改于 1268 天前,其中某些信息可能已经过时。
kubectl get pods -n namespace
kubectl get pods -n namespace -o wide 查看详细信息
kubectl get nodes -n namespace
kubectl describe pod -n namespace pod名 查看某个特定的pod描述
kubectl cluster-info 查看集群
kubectl get secret 得到保密字典
kubectl get svc 查看服务
kubectl logs -f -n namespace pod名 查看日志 查看某个pod的日志是随时更新的,可以用来检查此pod的状态
kubectl get hr -n namespace
Kubectl get hr -n namespace hr名 -oyaml 查看yaml
Kubectl exec -it -n namespace podname sh 进入容器常用/bin/sh
kubectl delete limitranges default -n <ns-name> 删除容器配额
redis-cli -h 部署master的ip -p 6379 -a "密码" -c 连接redis
set a 1
get a
keys * 查看所有键值对
性能测试
1.基准数据
--什么样前提或者规模下的稳定性:
机器配置:
稳定性测试:平均的QPS,中位性能的稳定性,而不是满负荷测试稳定性
参数值:二维矩阵,不同参数的配置组合,形成不同的testcase,编写脚本去执行测试。
pod的配置的数,集群模式,规模数,影响性能的参数,以及其他的参数列出来。
单点模式,高可用模式(主从),数据的规模,机器配置,读性能,写性能
服务连接方式:serviceIP,nodeIP,或者负载均衡。
2.需求:
数据规模:10W、20W、50W
测试结果:insert、select、QPS、数据刷新后插入查询等
场景:边插入边查询 数据刷新后插入查询
规格:集群节点数量,每个节点的resource limit,node上的背景负载(cpu、内存、网络)
性能参数:读性能和写性能 (QPS)
约束参数:cpu,内存,连接数,网络带宽
模式:集群模式、哨兵模式
3.redis性能测试资料:
1.客户需求
2.官方工具:https://redis.io/topics/benchmarks
3.测试教程:https://www.runoob.com/redis/redis-benchmarks.html
docker ps -a
docker images 查看本地镜像
docker pull imagename
docker push imagename
docker tag image-old image-new
docker exec -it podid /bin/bash 进入容器
原因一 远程仓库无镜像
kubectl describe pod -n <namespace> <失败的pod的名称>
查看event报错信息。
从日志中看哪一个镜像报错,比如是pull redisexporter1.0失败。
解决方式:
1.查看远程仓库是否有该镜像:docker pull harbor-b.alauda.cn/3rdparty/opstree/redis-exporter:1.0 <一般情况下都是因为没有这个镜像,然后就报错了。>
2.拉取远程仓库镜像,并重新打标签<tag>上传到远程仓库
举例:docker pull harbor.alauda.cn/3rdparty/opstree/redis-exporter:1.0
docker tag harbor.alauda.cn/3rdparty/opstree/redis-exporter:1.0 harbor-b.alauda.cn/3rdparty/opstree/redis-exporter:1.0
docker push harbor-b.alauda.cn/3rdparty/opstree/redis-exporter:1.0
上传成功后重启pod即可。
原因二 凭证失效
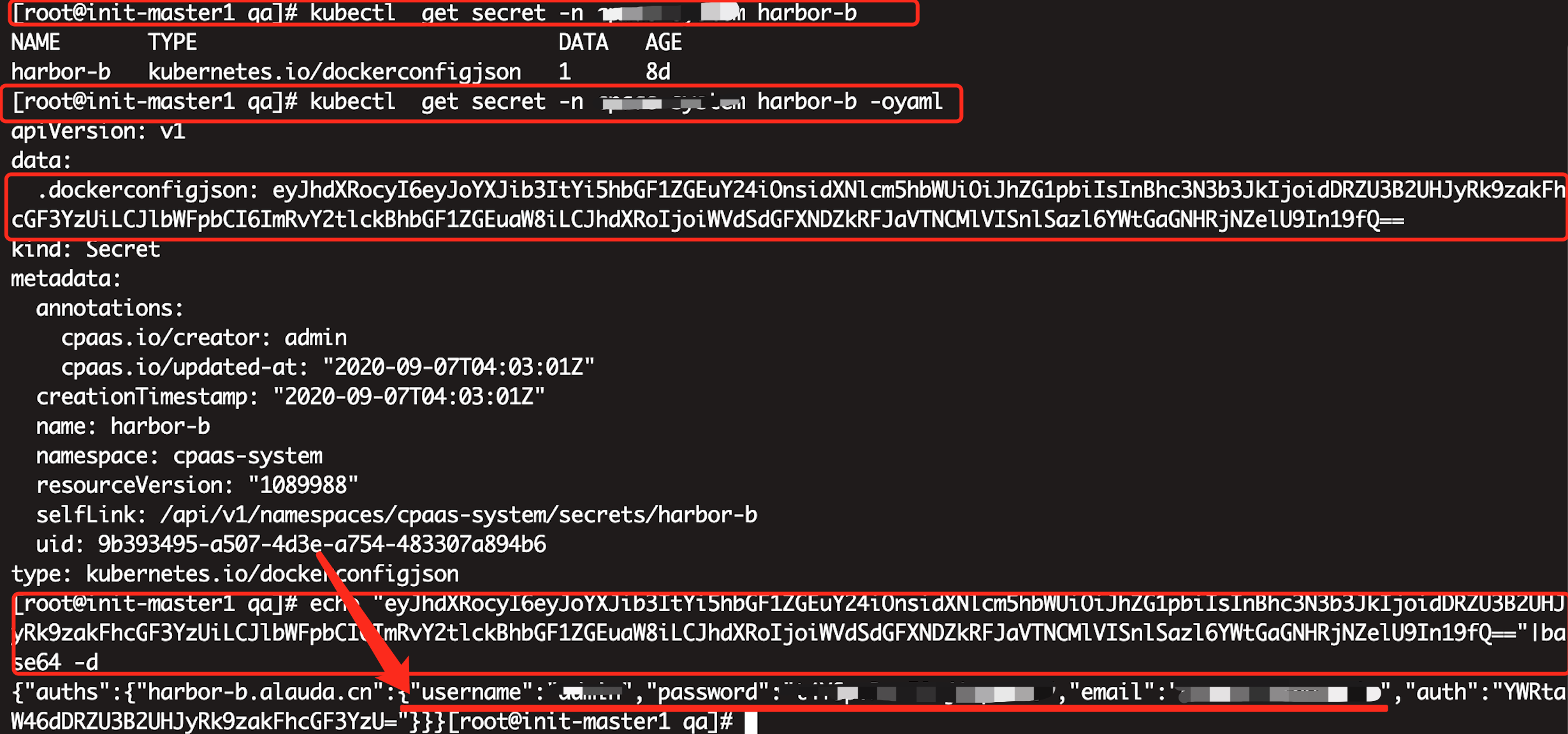
直接看笑笑写的文档(需要http代理):
http://confluence.alauda.cn/pages/viewpage.action?pageId=75075863
首先点进详情页查看容器组状态,有可能是没有存储类,也可能是拉取镜像失败,不需要当成bug上报,可以按照拉取镜像失败的方式处理,也可以进一步看一下pod报错的详细yaml。
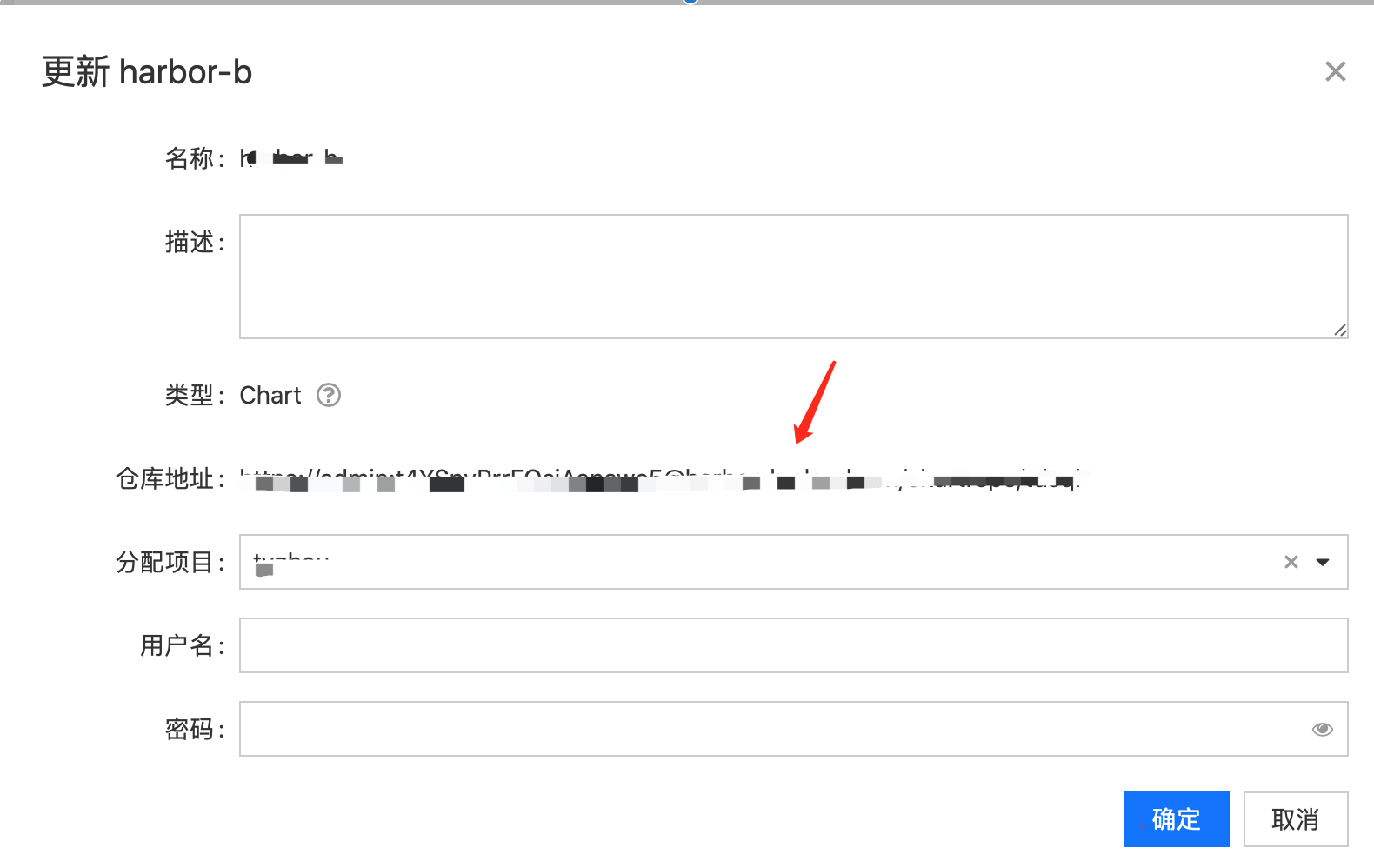

使用新的olm包需要确认拉取的镜像仓库有没有同步
kubectl get hr-name -n cpaas-system
得到name再edit
kubectl edit hr-name -n cpaas-system name
修改要拉取镜像的版本号,有时需要更新前端组件才能生效。
这里直接查看对应命名空间的同名pod,因为会起一个同名的pod来拉取镜像,可以发现ImagePullBackOff的话,说明对应环境仓库无镜像,用有权限的机器去拉取镜像然后tag上传即可。
显示绑不上持久卷应该先去对应的存储那里查看,试一下新建另一个持久卷声明,看能够绑定,如果同样绑不上的话说明是那个默认的存储类有问题,比如cephfs有问题。
kubectl get pod cpaas-system|grep ceph
查看对应的pod有起来吗,如果没有点击创建持久卷部署cephfs,或者重建默认cephfs(注意监视节点),kill pod重新启动。
1.挂载数据常用方式
-存储卷声明 写目录路径即可 生成数据文件 可以通过重启pod验证
-配置字典 声明需要写文件路径(否则会启动失败)
-空目录 只能用于pod下同一组容器组里互相传输数据,pod消失则数据消失
-主机目录 挂载在物理主机实际路径之下
2.删掉实例后对应的计算和部署会删掉,包括内部路由以及配置,但是不会删掉对应的pvc,需要手动删除。
第一次使用confluence和jira,蛮好用的,使用新工具都好激动
TestLink
gitLab
老是拎不清现在哪一个环节了,哪一个版本哪一个环境哪一轮了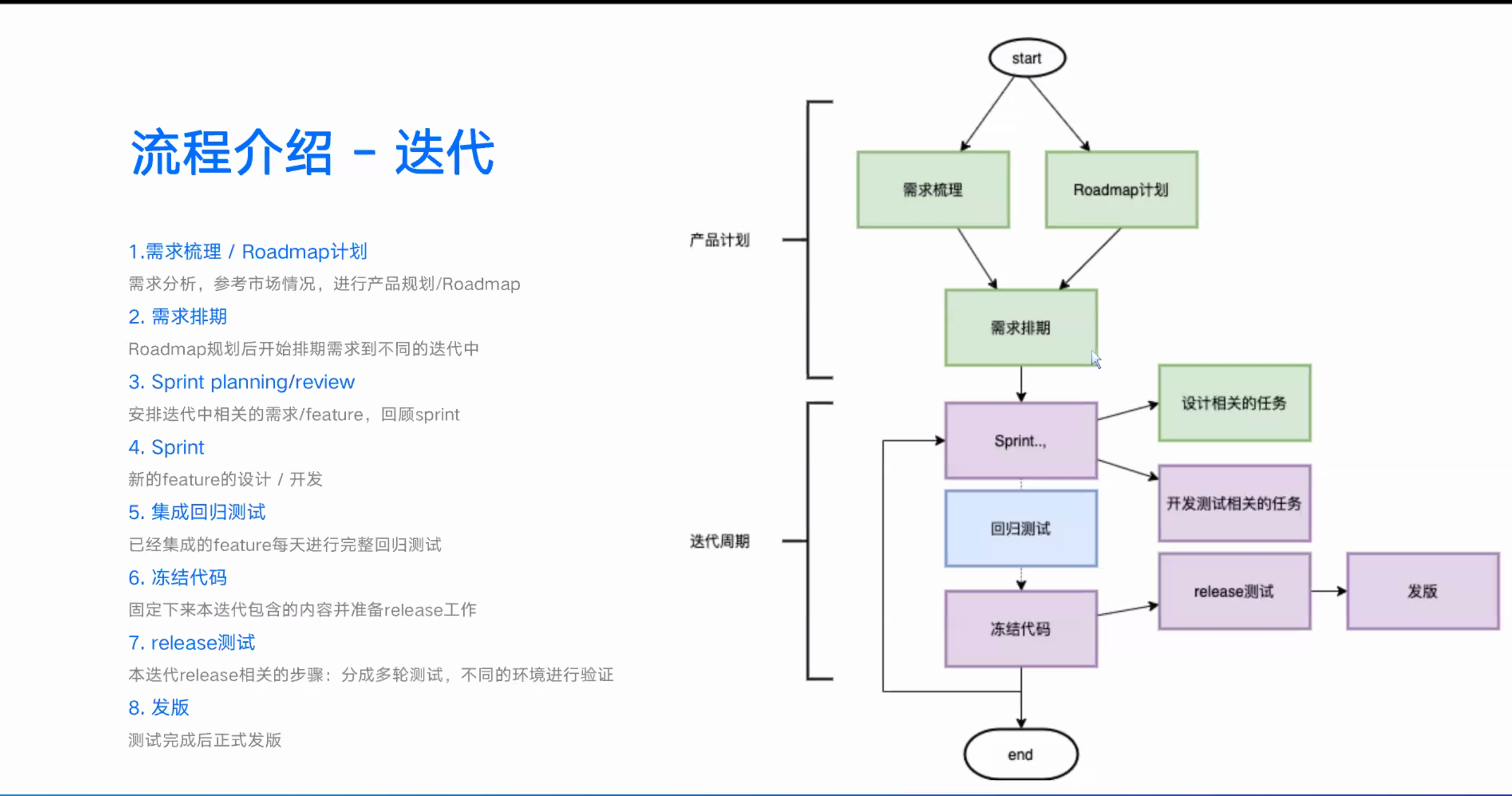
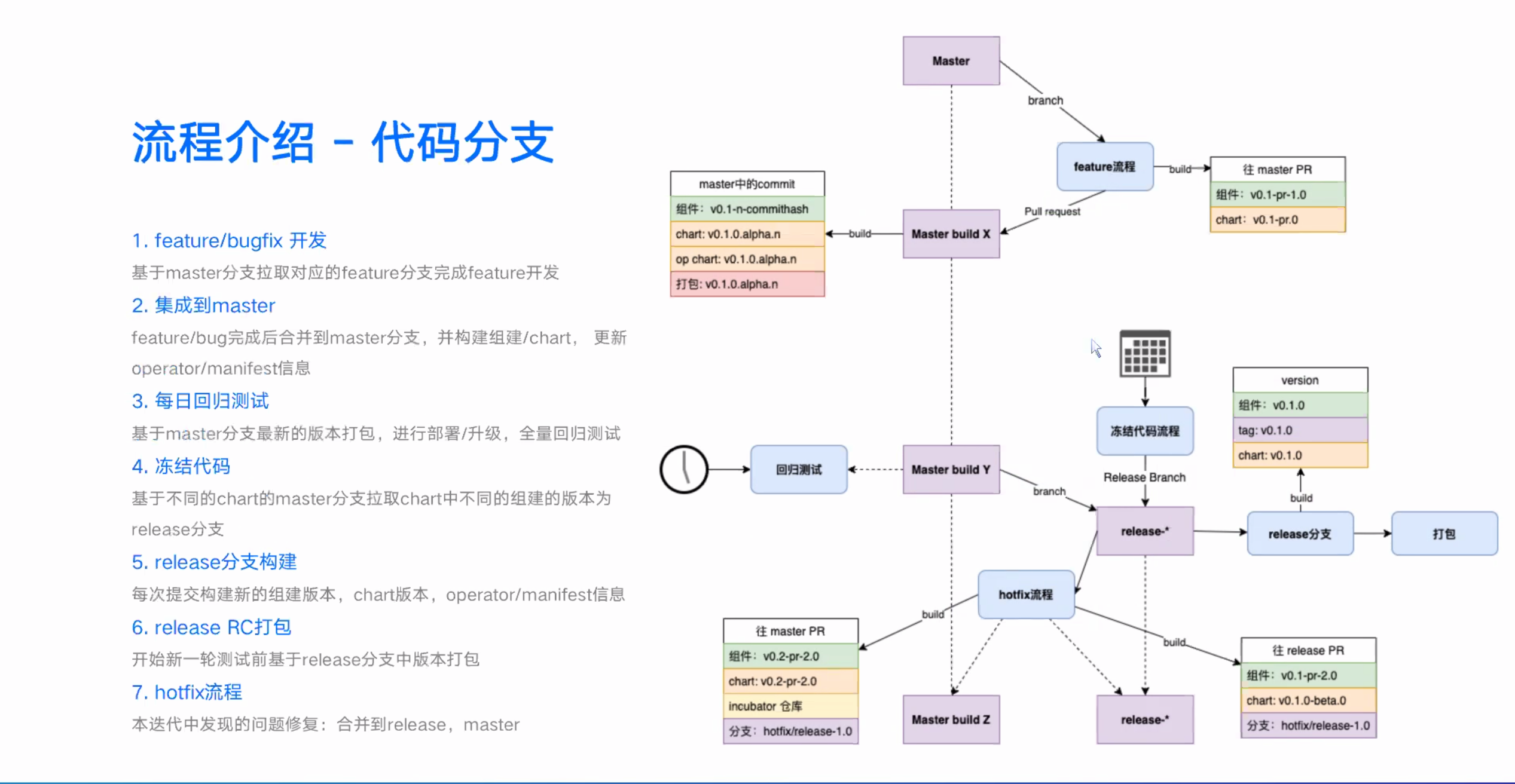
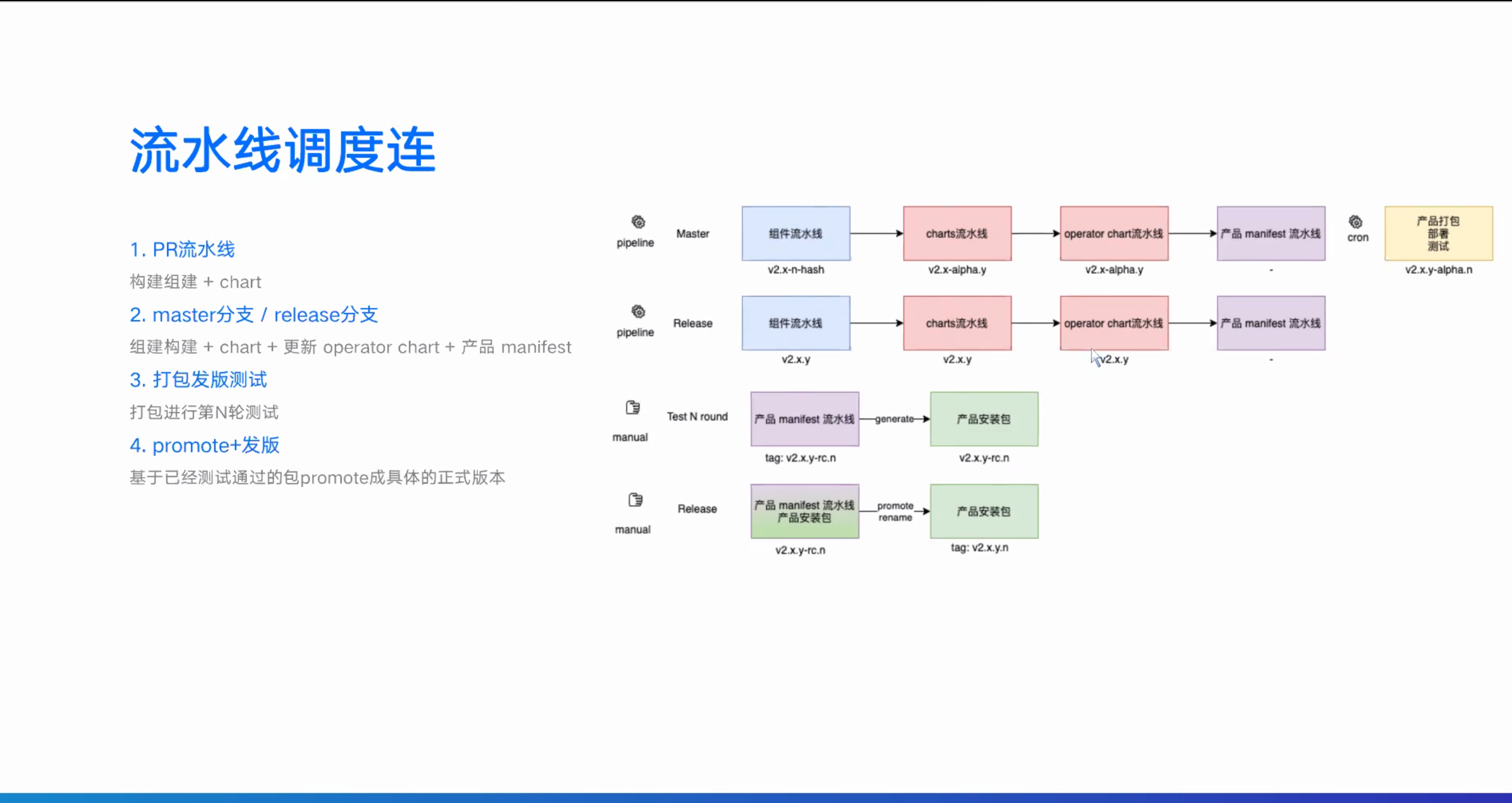
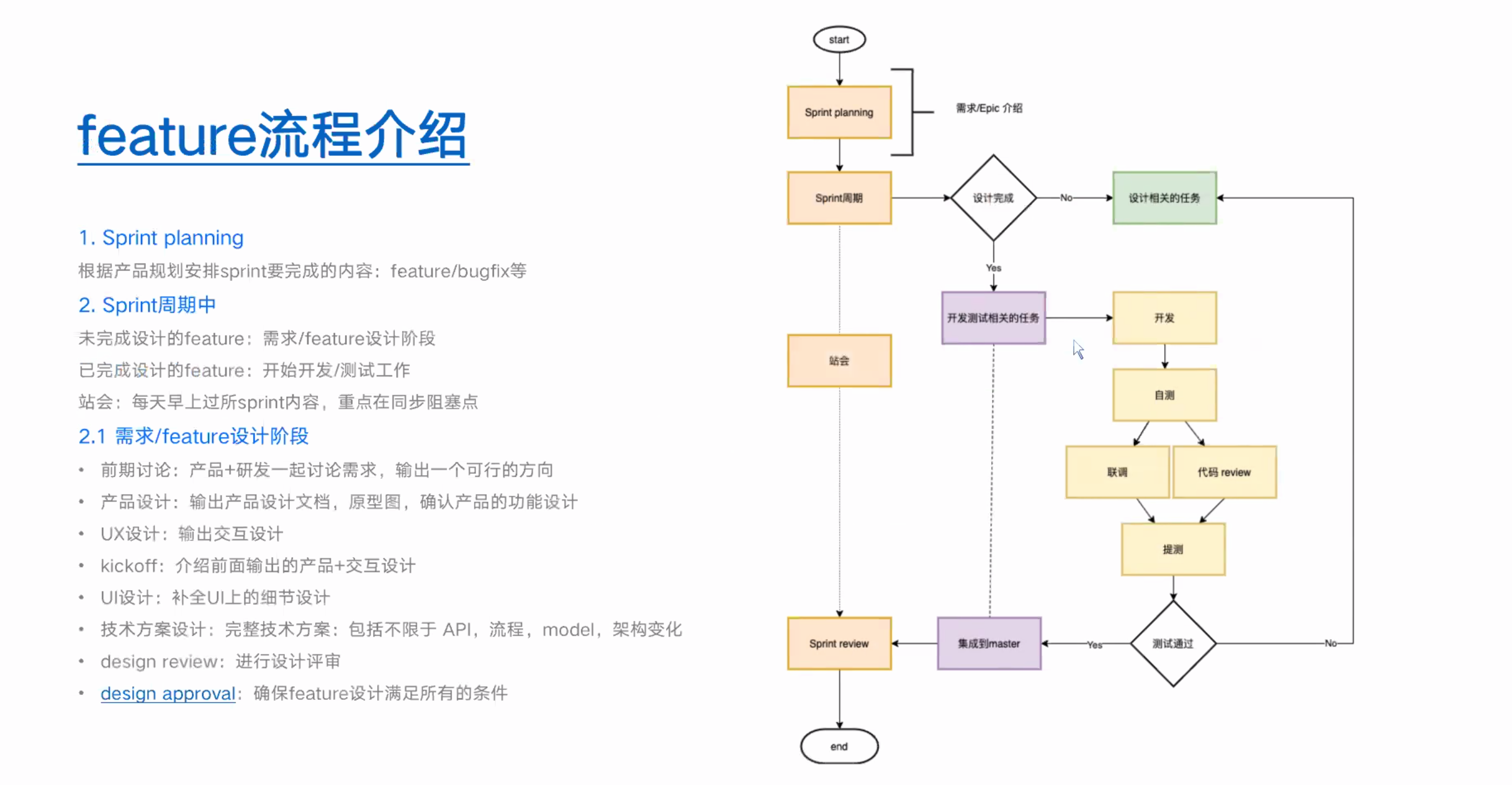

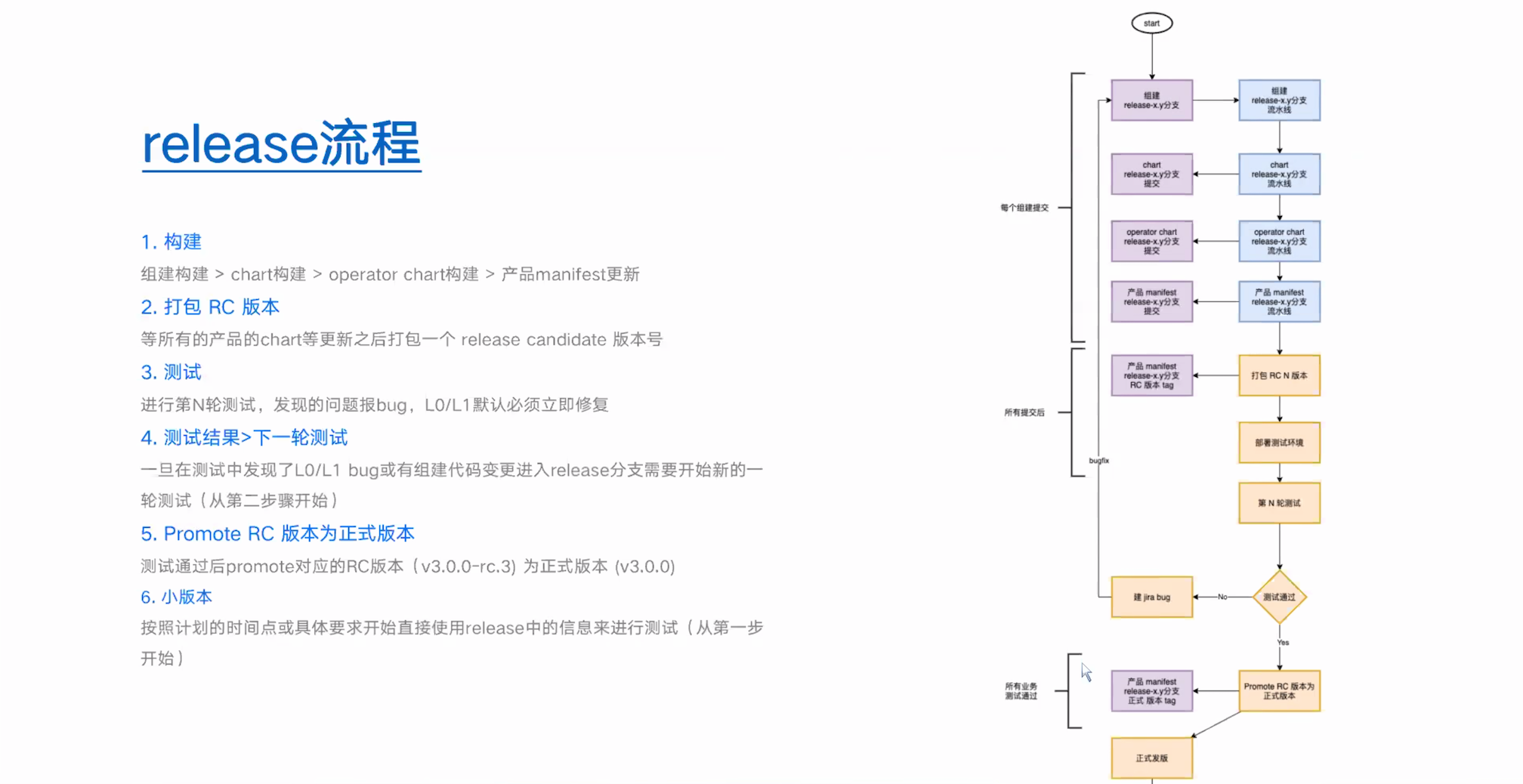
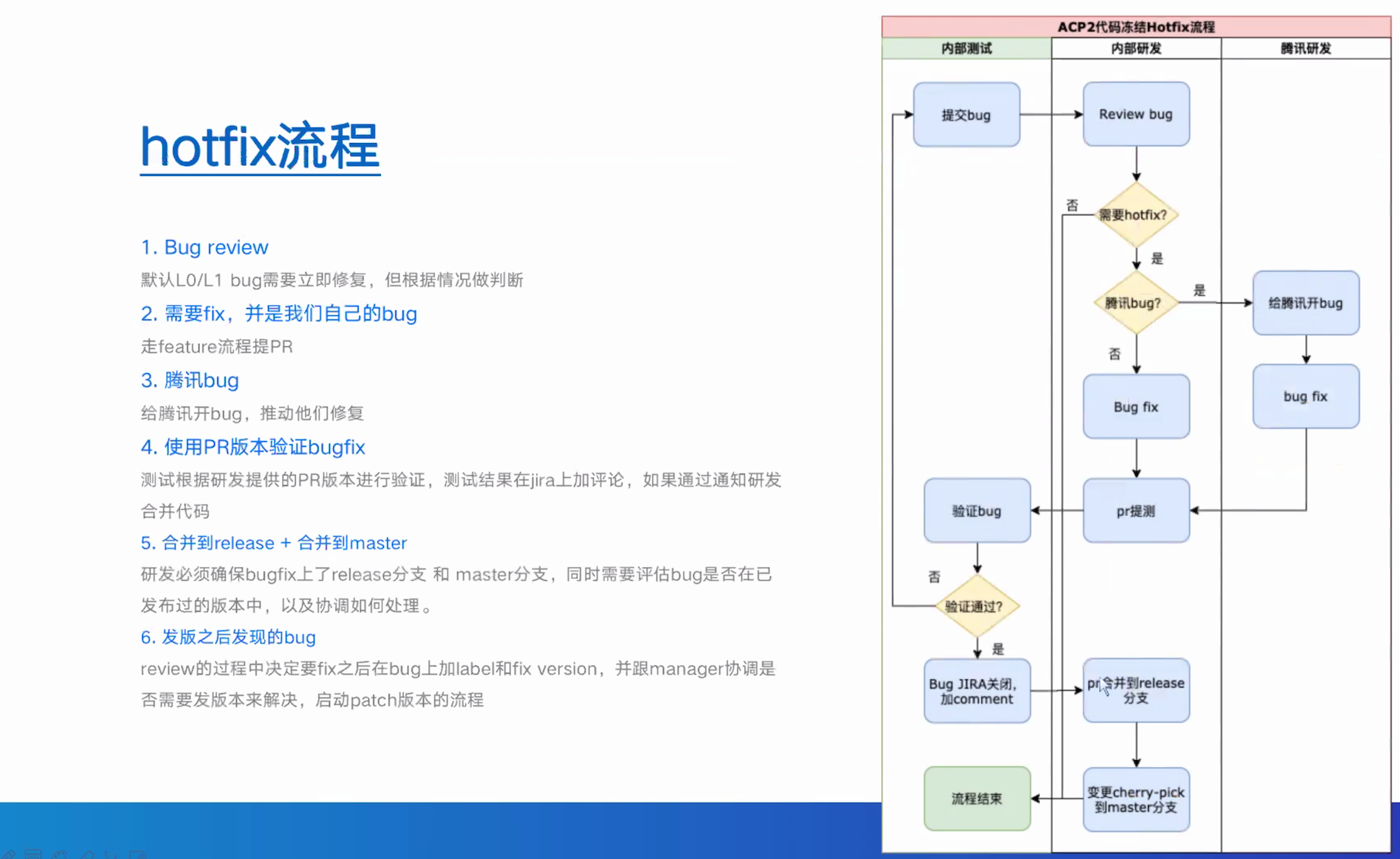
以下和知识无关
最值得纪念的还是第一个自己在jira上提的bug
被mentor带着第一次“硬刚”研发(平时自己和研发那边说话都好怂一直嗯嗯好的没事/捂脸)
和笑笑老是麻烦师父
周五啦,也要封版了这周的事情都完了,下班前的悠闲快乐时光//▽//









































































































全部评论 (暂无评论)
info 还没有任何评论,你来说两句呐!